Randomized rounding
Within computer science and operations research, many combinatorial optimization problems are computationally intractable to solve exactly (to optimality). Many such problems do admit fast (polynomial time) approximation algorithms—that is, algorithms that are guaranteed to return an approximately optimal solution given any input.
Randomized rounding (Raghavan & Tompson 1987) is a widely used approach for designing and analyzing such approximation algorithms.[1][2] The basic idea is to use the probabilistic method to convert an optimal solution of a relaxation of the problem into an approximately optimal solution to the original problem.
Contents
|
Overview
The basic approach has three steps:
- Formulate the problem to be solved as an integer linear program (ILP).
- Compute an optimal fractional solution
 to the linear programming relaxation (LP) of the ILP.
to the linear programming relaxation (LP) of the ILP. - Round the fractional solution of the LP to an integer solution
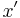 of the ILP.
of the ILP.
(Although the approach is most commonly applied with linear programs, other kinds of relaxations are sometimes used. For example, see Goeman's and Williamson's semi-definite programming-based Max-Cut approximation algorithm.)
The challenge in the first step is to choose a suitable integer linear program. (For example, the integer linear program should have a small integrality gap.) This challenge is not discussed here.
In the second step, the optimal fractional solution can typically be computed in polynomial time using any standard linear programming algorithm.
In the third step, the fractional solution must be converted into an integer solution (and thus a solution to the original problem). This is called rounding the fractional solution. The resulting integer solution should (provably) have cost not much larger than the cost of the fractional solution. This will ensure that the cost of the integer solution is not much larger than the cost of the optimal integer solution.
The main technique used to do this is to use randomization in the rounding process, and then to use probabilistic techniques to bound the increase in cost due to the rounding, following the probabilistic method from combinatorics. There, probabilistic arguments are used to show the existence of discrete structures with desired properties. In this context, one uses such arguments to show the following:
- Given any fractional solution of the LP, with positive probability the randomized rounding process produces an integer solution that approximates according to some desired criterion.
Finally, to make the third step computationally efficient, one either shows that approximates with high probability (so that the step can remain randomized) or one derandomizes the rounding step, typically using the method of conditional probabilities. The latter method converts the randomized rounding process into an efficient deterministic process that is guaranteed to reach a good outcome.
Comparison to other applications of the probabilistic method
The randomized rounding step differs from most applications of the probabilistic method in two respects:
- The computational complexity of the rounding step is important. It should be implementable by a fast (e.g. polynomial time) algorithm.
- The probability distribution underlying the random experiment is a function of the solution of a relaxation of the problem instance. This fact is crucial to proving the performance guarantee of the approximation algorithm --- that is, that for any problem instance, the algorithm returns a solution that approximates the optimal solution for that specific instance. In comparison, applications of the probabilistic method in combinatorics typically show the existence of structures whose features depend on other parameters of the input. For example, consider Turán's theorem, which can be stated as "any graph with
 vertices of average degree
vertices of average degree 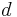 must have an independent set of size at least
must have an independent set of size at least 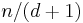 . (See this for a probabilistic proof of Turán's theorem.) While there are graphs for which this bound is tight, there are also graphs which have independent sets much larger than . Thus, the size of the independent set shown to exist by Turán's theorem in a graph may, in general, be much smaller than the maximum independent set for that graph.
. (See this for a probabilistic proof of Turán's theorem.) While there are graphs for which this bound is tight, there are also graphs which have independent sets much larger than . Thus, the size of the independent set shown to exist by Turán's theorem in a graph may, in general, be much smaller than the maximum independent set for that graph.
Set Cover example
The method is best illustrated by example. The following example illustrates how randomized rounding can be used to design an approximation algorithm for the Set Cover problem.
Fix any instance 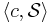 of the Set Cover problem over a universe
of the Set Cover problem over a universe 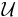 .
.
For step 1, let IP be the standard integer linear program for set cover for this instance.
For step 2, let LP be the linear programming relaxation of IP, and compute an optimal solution 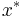 to LP using any standard linear programming algorithm. (This takes time polynomial in the input size.)
to LP using any standard linear programming algorithm. (This takes time polynomial in the input size.)
(The feasible solutions to LP are the vectors that assign each set 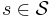 a non-negative weight
a non-negative weight 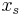 , such that, for each element
, such that, for each element 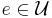 , covers
, covers 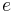 -- the total weight assigned to the sets containing is at least 1, that is,
-- the total weight assigned to the sets containing is at least 1, that is,
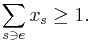
The optimal solution is a feasible solution whose cost
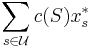
is as small as possible.)
Note that any set cover 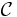 for
for 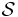 gives a feasible solution (where
gives a feasible solution (where 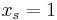 for
for 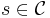 ,
, 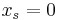 otherwise). The cost of this equals the cost of , that is,
otherwise). The cost of this equals the cost of , that is,
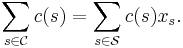
In other words, the linear program LP is a relaxation of the given set-cover problem.
Since has minimum cost among feasible solutions to the LP, the cost of is a lower bound on the cost of the optimal set cover.
Step 3: The randomized rounding step
Here is a description of the third step—the rounding step, which must convert the minimum-cost fractional set cover into a feasible integer solution (corresponding to a true set cover).
The rounding step should produce an that, with positive probability, has cost within a small factor of the cost of . Then (since the cost of is a lower bound on the cost of the optimal set cover), the cost of will be within a small factor of the optimal cost.
As a starting point, consider the most natural rounding scheme:
-
- For each set in turn, take
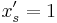 with probability
with probability 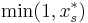 , otherwise take
, otherwise take 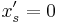 .
.
- For each set
With this rounding scheme, the expected cost of the chosen sets is at most 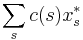 , the cost of the fractional cover. This is good. Unfortunately the coverage is not good. When the variables
, the cost of the fractional cover. This is good. Unfortunately the coverage is not good. When the variables 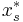 are small, the probability that an element is not covered is about
are small, the probability that an element is not covered is about
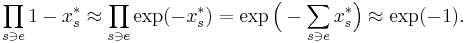
So only a constant fraction of the elements will be covered in expectation.
To make cover every element with high probability, the standard rounding scheme first scales up the rounding probabilities by an appropriate factor 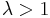 . Here is the standard rounding scheme:
. Here is the standard rounding scheme:
-
- Fix a parameter
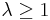 . For each set in turn,
. For each set in turn, - take with probability
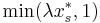 , otherwise take .
, otherwise take .
- Fix a parameter
Scaling the probabilities up by 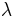 increases the expected cost by , but makes coverage of all elements likely. The idea is to choose as small as possible so that all elements are provably covered with non-zero probability. Here is a detailed analysis.
increases the expected cost by , but makes coverage of all elements likely. The idea is to choose as small as possible so that all elements are provably covered with non-zero probability. Here is a detailed analysis.
lemma (approximation guarantee for rounding scheme)
-
- Fix
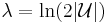 . With positive probability, the rounding scheme returns a set cover of cost at most
. With positive probability, the rounding scheme returns a set cover of cost at most 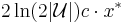 (and thus of cost
(and thus of cost 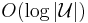 times the cost of the optimal set cover).
times the cost of the optimal set cover).
- Fix
(Note: with care the can be reduced to 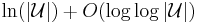 .)
.)
proof
The output of the random rounding scheme has the desired properties as long as none of the following "bad" events occur:
- the cost
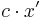 of exceeds
of exceeds 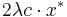 , or
, or - for some element , fails to cover .
The expectation of each 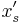 is at most
is at most 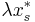 . By linearity of expectation, the expectation of is at most
. By linearity of expectation, the expectation of is at most 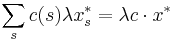 . Thus, by Markov's inequality, the probability of the first bad event above is at most
. Thus, by Markov's inequality, the probability of the first bad event above is at most 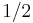 .
.
For the remaining bad events (one for each element ), note that, since 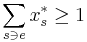 for any given element , the probability that is not covered is
for any given element , the probability that is not covered is
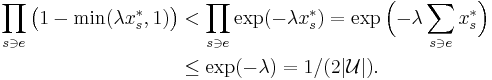
(This uses the inequality 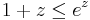 , which is strict for
, which is strict for 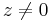 .)
.)
Thus, for each of the 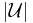 elements, the probability that the element is not covered is less than
elements, the probability that the element is not covered is less than 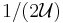 .
.
By the naive union bound, the probability that one of the 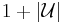 bad events happens is less than
bad events happens is less than 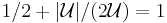 . Thus, with positive probability there are no bad events and is a set cover of cost at most . QED
. Thus, with positive probability there are no bad events and is a set cover of cost at most . QED
Derandomization using the method of conditional probabilities
The lemma above shows the existence of a set cover of cost 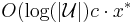 ). In this context our goal is an efficient approximation algorithm, not just an existence proof, so we are not done.
). In this context our goal is an efficient approximation algorithm, not just an existence proof, so we are not done.
One approach would be to increase a little bit, then show that the probability of success is at least, say, 1/4. With this modification, repeating the random rounding step a few times is enough to ensure a successful outcome with high probability.
That approach weakens the approximation ratio. We next describe a different approach that yields a deterministic algorithm that is guaranteed to match the approximation ratio of the existence proof above. The approach is called the method of conditional probabilities.
The deterministic algorithm emulates the randomized rounding scheme: it considers each set in turn, and chooses 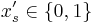 . But instead of making each choice randomly based on , it makes the choice deterministically, so as to keep the conditional probability of failure, given the choices so far, below 1.
. But instead of making each choice randomly based on , it makes the choice deterministically, so as to keep the conditional probability of failure, given the choices so far, below 1.
Bounding the conditional probability of failure
We want to be able to set each variable in turn so as to keep the conditional probability of failure below 1. To do this, we need a good bound on the conditional probability of failure. The bound will come by refining the original existence proof. That proof implicitly bounds the probability of failure by the expectation of the random variable
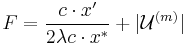 ,
,
where
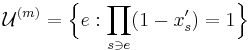
is the set of elements left uncovered at the end.
The random variable 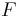 may appear a bit mysterious, but it mirrors the probabilistic proof in a systematic way. The first term in comes from applying Markov's inequality to bound the probability of the first bad event (the cost is too high). It contributes at least 1 to if the cost of is too high. The second term counts the number of bad events of the second kind (uncovered elements). It contributes at least 1 to if leaves any element uncovered. Thus, in any outcome where is less than 1, must cover all the elements and have cost meeting the desired bound from the lemma. In short, if the rounding step fails, then
may appear a bit mysterious, but it mirrors the probabilistic proof in a systematic way. The first term in comes from applying Markov's inequality to bound the probability of the first bad event (the cost is too high). It contributes at least 1 to if the cost of is too high. The second term counts the number of bad events of the second kind (uncovered elements). It contributes at least 1 to if leaves any element uncovered. Thus, in any outcome where is less than 1, must cover all the elements and have cost meeting the desired bound from the lemma. In short, if the rounding step fails, then 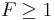 . This implies (by Markov's inequality) that
. This implies (by Markov's inequality) that ![E[F]](/2012-wikipedia_en_all_nopic_01_2012/I/5bdb1345299e3589b3a6eaed01266816.png) is an upper bound on the probability of failure. Note that the argument above is implicit already in the proof of the lemma, which also shows by calculation that
is an upper bound on the probability of failure. Note that the argument above is implicit already in the proof of the lemma, which also shows by calculation that ![E[F] < 1](/2012-wikipedia_en_all_nopic_01_2012/I/de8a5ed5391ca399c141b8ad2e7104eb.png) .
.
To apply the method of conditional probabilities, we need to extend the argument to bound the conditional probability of failure as the rounding step proceeds. Usually, this can be done in a systematic way, although it can be technically tedious.
So, what about the conditional probability of failure as the rounding step iterates through the sets? Since in any outcome where the rounding step fails, by Markov's inequality, the conditional probability of failure is at most the conditional expectation of .
Next we calculate the conditional expectation of , much as we calculated the unconditioned expectation of in the original proof. Consider the state of the rounding process at the end of some iteration 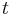 . Let
. Let 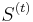 denote the sets considered so far (the first sets in ). Let
denote the sets considered so far (the first sets in ). Let 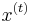 denote the (partially assigned) vector (so
denote the (partially assigned) vector (so 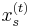 is determined only if
is determined only if 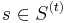 ). For each set
). For each set 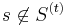 , let
, let 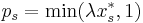 denote the probability with which will be set to 1. Let
denote the probability with which will be set to 1. Let 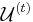 contain the not-yet-covered elements. Then the conditional expectation of , given the choices made so far, that is, given , is
contain the not-yet-covered elements. Then the conditional expectation of , given the choices made so far, that is, given , is
![E[F | x^{(t)}]
~=~
\frac{\sum_{s\in S^{(t)}} c(s) x'_s
%2B \sum_{s\not\in S^{(t)}} c(s) p_s}{2\lambda c\cdot x^*}
~%2B~
\sum_{e\in \mathcal U^{(t)}}\prod_{s\not\in S^{(t)}, s\ni e} (1-p_s).](/2012-wikipedia_en_all_nopic_01_2012/I/95090cc679b2bfb11e78b6400509f409.png)
Note that ![E[F | x^{(t)}]](/2012-wikipedia_en_all_nopic_01_2012/I/ce96b87bda5c4a134f957d3258d57df1.png) is determined only after iteration .
is determined only after iteration .
Keeping the conditional probability of failure below 1
To keep the conditional probability of failure below 1, it suffices to keep the conditional expectation of below 1. To do this, it suffices to keep the conditional expectation of from increasing. This is what the algorithm will do. It will set in each iteration to ensure that
![E[F|x^{(m)}] \le E[F|x^{(m-1)}] \le \cdots \le E[F|x^{(1)}] \le E[F|x^{(0)}] < 1](/2012-wikipedia_en_all_nopic_01_2012/I/cbdffafd5d699339625f5003cc95d309.png)
(where 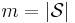 ).
).
In the th iteration, how can the algorithm set 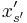 to ensure that
to ensure that ![E[F|x^{(t)}] \le E[F|S^{(t-1)}]](/2012-wikipedia_en_all_nopic_01_2012/I/8de870f24563bbc1984a4e343db54deb.png) ? It turns out that it can simply set so as to minimize the resulting value of .
? It turns out that it can simply set so as to minimize the resulting value of .
To see why, focus on the point in time when iteration starts. At that time, ![E[F|x^{(t-1)}]](/2012-wikipedia_en_all_nopic_01_2012/I/5dd07f0080ec4b52eb3c66ae5b97674b.png) is determined, but is not yet determined --- it can take two possible values depending on how is set in iteration . Let
is determined, but is not yet determined --- it can take two possible values depending on how is set in iteration . Let 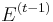 denote the value of
denote the value of ![E[F|x'^{(t-1)}]](/2012-wikipedia_en_all_nopic_01_2012/I/2c97980cfd8198b82cc27ab2f293c2b4.png) . Let
. Let 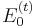 and
and 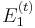 , denote the two possible values of , depending on whether is set to 0, or 1, respectively. By the definition of conditional expectation,
, denote the two possible values of , depending on whether is set to 0, or 1, respectively. By the definition of conditional expectation,
![E^{(t-1)} ~=~
\Pr[x'_{s'}=0] E^{(t)}_0
%2B
\Pr[x'_{s'}=1] E^{(t)}_1.](/2012-wikipedia_en_all_nopic_01_2012/I/8809f46cde4ffd6c3d0a17eb38283d87.png)
Since a weighted average of two quantities is always at least the minimum of those two quantities, it follows that
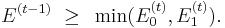
Thus, setting so as to minimize the resulting value of will guarantee that ![E[F | x^{(t)}] \le E[F | x^{(t-1)}]](/2012-wikipedia_en_all_nopic_01_2012/I/73b55f7189b53cd0a2a050a20bb526ea.png) . This is what the algorithm will do.
. This is what the algorithm will do.
In detail, what does this mean? Considered as a function of (with all other quantities fixed) is a linear function of , and the coefficient of in that function is
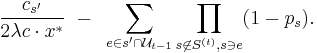
Thus, the algorithm should set to 0 if this expression is positive, and 1 otherwise. This gives the following algorithm.
Randomized-rounding algorithm for Set Cover
input: set system , universe , cost vector 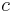
output: set cover (a solution to the standard integer linear program for set cover)
- Compute a min-cost fractional set cover (an optimal solution to the LP relaxation).
- Let
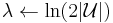 . Let
. Let 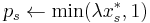 for each .
for each . - For each
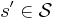 do:
do:
- Let
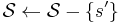 . ( contains the not-yet-decided sets.)
. ( contains the not-yet-decided sets.) - If
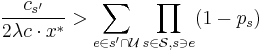
- then set
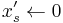 ,
, - else set
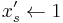 and
and 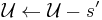 .
. - ( contains the not-yet-covered elements.)
- then set
- Let
- Return .
lemma (approximation guarantee for algorithm)
-
- The algorithm above returns a set cover of cost at most
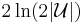 times the minimum cost of any (fractional) set cover.
times the minimum cost of any (fractional) set cover.
- The algorithm above returns a set cover
proof
The algorithm ensures that the conditional expectation of , ![E[F \,|\, x^{(t)}]](/2012-wikipedia_en_all_nopic_01_2012/I/3aa209f4edc6940e5ef6e1c241c5363a.png) , does not increase at each iteration. Since this conditional expectation is initially less than 1 (as shown previously), the algorithm ensures that the conditional expectation stays below 1. Since the conditional probability of failure is at most the conditional expectation of , in this way the algorithm ensures that the conditional probability of failure stays below 1. Thus, at the end, when all choices are determined, the algorithm reaches a successful outcome. That is, the algorithm above returns a set cover of cost at most times the minimum cost of any (fractional) set cover.
, does not increase at each iteration. Since this conditional expectation is initially less than 1 (as shown previously), the algorithm ensures that the conditional expectation stays below 1. Since the conditional probability of failure is at most the conditional expectation of , in this way the algorithm ensures that the conditional probability of failure stays below 1. Thus, at the end, when all choices are determined, the algorithm reaches a successful outcome. That is, the algorithm above returns a set cover of cost at most times the minimum cost of any (fractional) set cover.
Remarks
In the example above, the algorithm was guided by the conditional expectation of a random variable . In some cases, instead of an exact conditional expectation, an upper bound (or sometimes a lower bound) on some conditional expectation is used instead. This is called a pessimistic estimator.
See also
References
- ^ Motwani, Rajeev; Raghavan, Prabhakar. Randomized algorithms. Cambridge University Press. ISBN 9780521474658. http://books.google.com/books?id=QKVY4mDivBEC&q=randomized+rounding#v=snippet&q=randomized%20rounding&f=false.
- ^ Vazirani, Vijay. Approximation algorithms. Springer Verlag. ISBN 9783540653677. http://books.google.com/books?id=EILqAmzKgYIC&dq=vazirani+approximation+algorithms+doi+isbn&printsec=frontcover&source=bn&hl=en&ei=3PSzS4-BO4TUNZSF4Z0J&sa=X&oi=book_result&ct=result&resnum=5&ved=0CCYQ6AEwBA#v=snippet&q=%22randomized%20rounding%22&f=false.
- Raghavan, Prabhakar; Tompson, Clark D. (1987), "Randomized rounding: A technique for provably good algorithms and algorithmic proofs", Combinatorica 7 (4): 365–374, doi:10.1007/BF02579324.
- Raghavan, Prabhakar (1988), "Probabilistic construction of deterministic algorithms: approximating packing integer programs", Journal of Computer and System Sciences 37 (2): 130–143, doi:10.1016/0022-0000(88)90003-7.
Further reading
- Althöfer, Ingo (1994), "On sparse approximations to randomized strategies and convex combinations", Linear Algebra and its Applications 199: 339–355, doi:10.1016/0024-3795(94)90357-3, MR1274423
- Hofmeister, Thomas; Lefmann (1996), "Computing sparse approximations deterministically", Linear Algebra and its Applications 240: 9–19, MR1387283
- Lipton, Richard J.; Young, Neal E. (1994), "Simple strategies for large zero-sum games with applications to complexity theory", STOC '94: Proceedings of the twenty-sixth annual ACM symposium on theory of computing, Montreal, Quebec, Canada: ACM, pp. 734–740, doi:10.1145/195058.195447, ISBN 0-89791-663-8